






Perception and Physiological Responses to Odours
Wendy Powers of Michigan State University explains the terminology used to describe odorants and odour, how the human olfactory system works, and how humans respond to odour. 12 February 2013
12 February 2013
 8 minute read
8 minute read
 By:
By: Introduction
Olfaction, the sense of smell, is the least understood of the five human senses. This, among other factors, makes the task of reducing livestock odours a considerable challenge. This factsheet explains the terminology used to describe odorants and odour, how the human olfactory system works, and how humans respond to odour.
Objectives
The objectives of this factsheet are to:
- define odour and how perception is quantified
- describe the human olfactory system and how it responds to odour, and
- describe how the human olfactory system adapts to odour.
Odour Terminology and Perception
An odorant is a substance capable of eliciting an olfactory response whereas odour is the sensation resulting from stimulation
of the olfactory organs. Odours play an important part in our everyday life, from appetite stimulation to serving
as warning signals for disease detection. A number of diseases have characteristic odours including gangrene, diabetes,
leukemia, and schizophrenia. Odours have been implicated in depression and nausea as well.
Detectable odours can have a significant impact on people by affecting human emotions as well as having physiological
impacts on the olfactory system. People associate odours with past experiences and, from those experiences, involuntarily
assess the odour as likable, dislikable or indifferent. Effects on individuals, however, vary from one person to another.
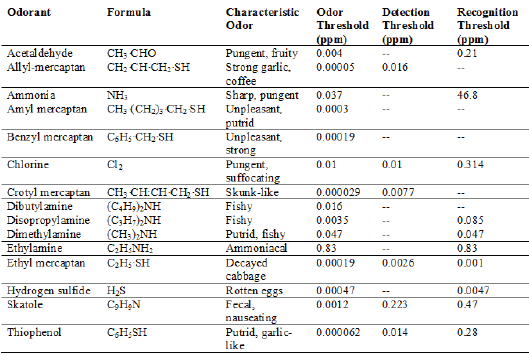
Odour threshold is a term used to identify the concentration at which animals respond 50 per cent of the time to repeated
presentations of an odorant. This term is reserved, primarily, for use in research with animals. Most often, however, odour
threshold is interpreted as detection threshold, which identifies the odour concentration at which 50 per cent of a human
panel can identify the presence of an odour or odorant without characterising the stimulus. Detection threshold is the
term most frequently used when discussing odour research results associated with livestock operations. The recognition
threshold is the concentration at which 50 per cent of the human panel can identify the odorant or odour, such as the smell
of ammonia or peppermint.
Although the detection threshold concentrations of substances that evoke a smell are slight (Table 1), a concentration
only 10 to 50 times above the detection threshold value often is the maximum intensity that can be detected by humans.
This, however, is in contrast to other sensory systems where maximum intensities are many more multiples of threshold
intensities. The maximum intensity of sight, for instance, is about 500,000 times that of the threshold intensity and a factor
of one trillion is observed for hearing. For this reason, smell often identifies the presence or absence of odour rather than
quantifies its intensity or concentration.
The ability to perceive an odour varies widely among individuals. More than a thousand-fold difference between the least
and the most sensitive individuals in acuity have been observed. Differences between individuals are, in part, attributable
to age, smoking habits, gender, nasal allergies, head colds or other illnesses. Non-smokers over the age of 15 show
greater sensitivity than smokers in general. Furthermore, females tend to have a keener sense of smell than males, a finding
that has been substantiated in work at Iowa State University.
Generally, the olfactory sensory nerves atrophy from the
time of birth to the extent that only 82 per cent of the acuity remains at the age of 20; 38 per cent at the age of 60 and 28
per cent at the age of 80. Consequently, olfactory acuity and like or dislike of an odour decrease with age.
Infants appear to like all classes of odorous materials, perhaps because of the lack of previous experience and because
of their innate curiosity. Children younger than five years old rated sweat and faeces as pleasant but above that age, as
unpleasant.
Like and dislike of a particular odour can change with odour concentration or intensity. Generally, humans can
distinguish between more than 5,000 odours but some individuals experience anosmia (smell blindness) for one or more
odours. In this situation, the individual apparently has a normal sense of smell but is unable to detect one particular odour
regardless of its intensity. For example, because methyl mercaptan has an odour recognition threshold of only 0.0021ppm
(Table 1), it is often mixed with natural gas as an indicator of leaks; however, approximately one in 1,000 persons
is unable to detect the strong odour of this mercaptan. An estimated 30 per cent of the elderly have lost the ability to perceive
the minute amount of this mercaptan used in natural gas.
Odour Physiology
Olfaction depends upon the interaction between the odour stimulus and the olfactory epithelium. The olfactory membrane is a sensitive area, covering 4 to 6 square centimetres in each nostril (Figure 1).
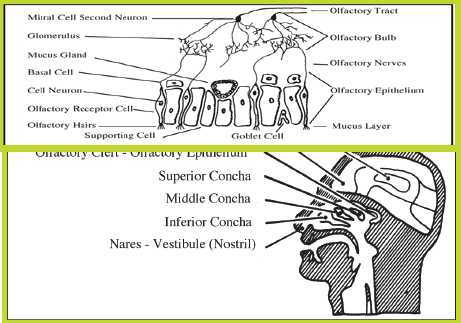
Below: Figure 2. The olfactory system
Beneath
the membrane is a mucous layer. The nerve cells
or peripheral receptor cells that primarily sense
odours and fragrances are located in the epithelium.
Cilia extend from the nerve cells into the mucous
layer, which greatly increases the potential receptor
area. The cilia are thought to contain the ultimate
olfactory receptors, which are specialised protein
molecules. Specific anosmia may result from the
inability to synthesise the appropriate protein. The
receptor cells transmit impulses to the olfactory
bulb located at the base of the front brain (Figure 2).
At the bulb, fibres from the nose contact with other
nerves, which travel on to various parts of the brain.
In order for there to be a sensation the following
are important:
- the substance must be volatile enough to permeate the air near the sensory area
- the substance must be at least slightly water-soluble to pass through the mucous layer and to the olfactory cells
- the substance must be lipid-soluble because olfactory cilia are composed primarily of lipid material, and finally
- a minimum number of odourous particles must be in contact with the receptors for a minimum length of time.
Many theories have been proposed to describe the mechanism of smelling odours. Most can be classified into one of two
groups: a physical theory or a chemical theory. The physical theory proposes that the shape of the odourant molecule
determines which olfactory cells will be stimulated and, therefore, what kind of odour will be perceived. Each receptor
cell has several different types of molecular receptor sites, and selection and proportion of the various sites differ from
cell to cell.
The chemical theory, which is more widely accepted, assumes that the odorant molecules bind chemically to protein
receptors in the membranes of the olfactory cilia. The type of receptor in each olfactory cell determines the type of stimulant
that will excite the cell. Binding to the receptor indirectly creates a receptor potential in the olfactory cell that generates
impulses in the olfactory nerve fibres. Receptor sensitivity may explain some of the variation in detection thresholds
exhibited by different compounds. For example, ammonia has an odour threshold of 0.037ppm whereas the corresponding
values for hydrogen sulphide and sulphur dioxide are 0.00047 and 0.009ppm, respectively (Table 1).
Odour Responses
Odour adaptation is the process by which one becomes accustomed to an odour. The adaptation time needed is greater
when more than one odour is present. When adaptation occurs, the detection
threshold increases. The detection threshold limits change faster when
an odour of high, rather than low, intensity is presented. Besides, adaptation
occurs differently for each odour. Odour fatigue occurs when total adaptation
to a particular odour has occurred through prolonged exposure. This situation would apply to swine production workers or
managers who are exposed to the smell of swine manure on a daily basis and appear virtually unaware of the odour.
While ammonia and hydrogen sulphide are odorants, and not odours per se, they are produced through processes often
associated with odour, including municipal sewage treatment systems, coal burning, industries and factories, and livestock
operations.
Both ammonia and hydrogen sulphide can cause olfactory losses as a result of chronic or prolonged exposure. Ammonia
also can affect the central nervous system. A number of other chemical pollutants, including some insecticides result in
losses in olfaction by damaging olfactory receptors. The use of medications may exacerbate chemosensory disorders.
On average, olfactory receptors renew themselves every 30 days. Pollutants may alter this turnover rate or disrupt the
integrity of the lipid membranes of olfactory receptors. Threshold levels have been identified for a number of pollutants,
above which odour or irritation occur. Unfortunately, however, knowledge of the exact mechanisms by which pollutants
alter olfaction is limited.
Summary
Odour science is complex and olfaction is the least understood of the five senses. Odour is the sensation resulting from an odorant stimulating the olfactory system.
The four factors that influence when a stimulation occur are the volatility of the
substance, the water and lipid solubility of the substance, and the number of particles in contact with the odour receptors
over time. However, age, gender, exposure and experience also impact the response to odorants or odour. Human response to odour is quantified by the detection and recognition thresholds, which occur when 50 per cent of a human panel can
detect the presence of, or recognise the odorant or odour, respectively.
References cited and additional resources
1. Water Environment Federation. 1978. Odor Control for Wastewater Facilities. Manual of Practice No. 22. Water Pollution Control Federation, Washington D.C.
2. Powers-Schilling, W.J. 1995. Olfaction: chemical and psychological considerations. Proc. of Nuisance Concerns in Animal
Management: Odor and Flies Conference, Gainesville, Florida, March 21-22.
This paper is adapted from 'The Science of Smell Part 1: Odor perception and physiological response' by Wendy Powers, Iowa State University Extension Publication PM 1963A, May 2004 and can be found on the Air Quality and Animal Agriculture Web page.
February 2013

